Multiview Masked Autoencoders for 3D Vision
Artificial Intelligence
Computer Vision
Vision Science
The remarkable progress of AI models in various domains is largely due to scale; in terms of model parameters, computational hardware, and labeled data. Despite training on extensive internet data, AI models often fail to match human perception, particularly in out-of-distribution generalization, semantic reasoning, and sample efficiency.
How do we instill these capabilities in AI models?
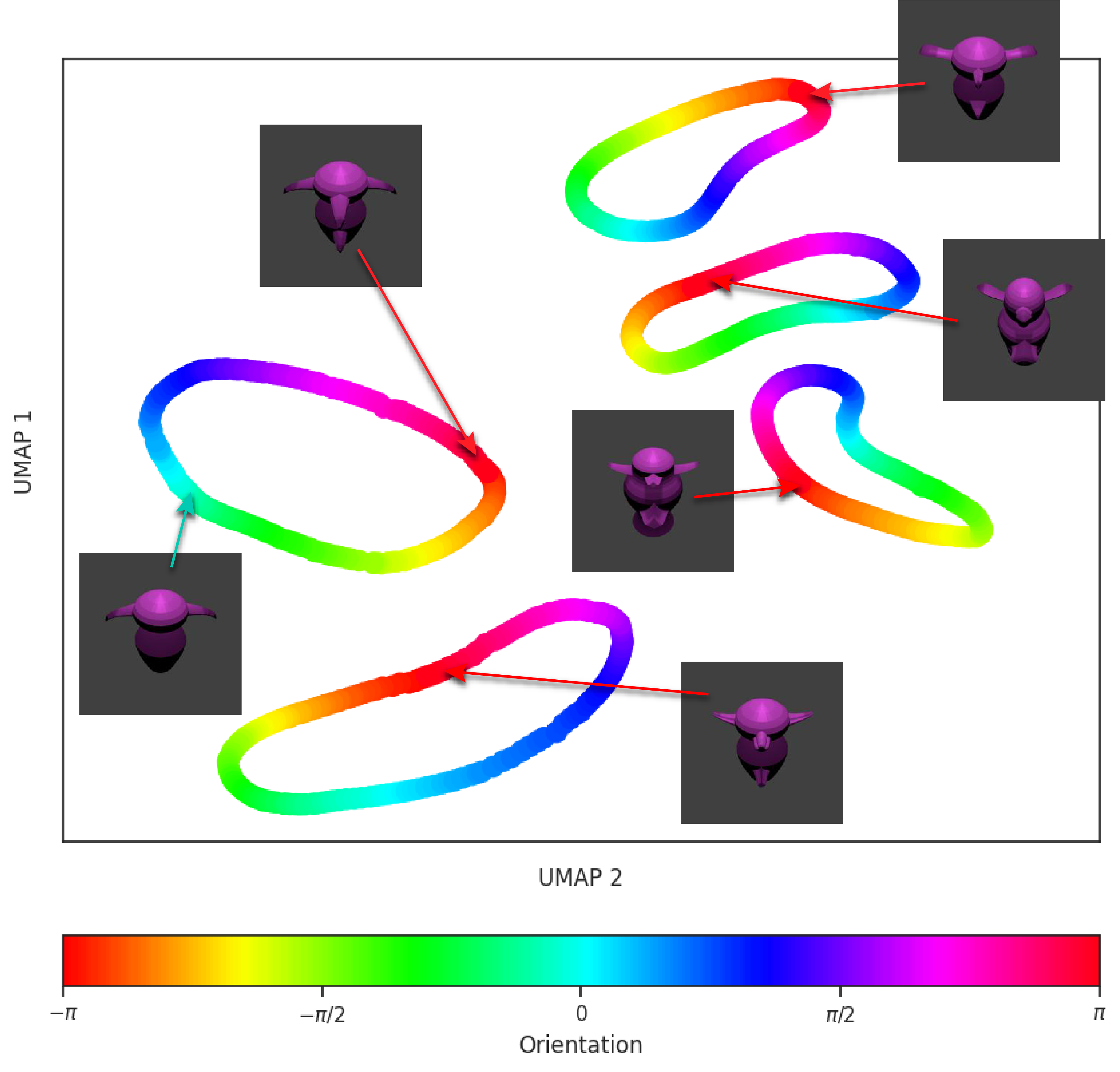
In an attempt to answer this question, we hypothesized that learning regimes and objective functions akin to human visual development could instill models with these innate human abilities. This project aims to develop robust, interpretable, and grounded representations using multi-view spatiotemporal data. We generated this data through neural radiance fields (NeRFs) to create 3D models and sequences from camera-captured videos using 3D Gaussian Splatting. We trained a novel spatiotemporal vision model with a causal vision modeling objective inspired by human visual development. The evaluation of our model’s representations on out-of-distribution spatiotemporal data showed it learned equivariance to new viewpoints, enhancing interpretability and human alignment.
Technologies Used: PyTorch, TPUs, ViT.
My Role:
- We trained a novel spatiotemporal vision model with a causal vision modeling objective.
- Refactored CUDA code to run on TPUs using PyTorch XLA.
- Scripting to spawn and train on TPUs.
- Ran over 400 training runs to train Transformer-based models on large-scale data.
- Analyzed the learned representations in projection spaces.