Mouse Behavior Tracking
Artificial Intelligence
Computer Vision
Vision Science
Behavioral Analysis
Complex naturalistic behavior is composed of sequences of stereotyped behavioral syllables, which combine to generate rich sequences of actions. We aim to extract a latent representation from unlabelled behavioral videos of specimens using two approaches. First, computer vision and pose estimation techniques are utilized to compute the pose of the specimen. We learn canonical poses and their transitions wielding stochastic processes from generative and Markov models. While this approach has been successful in extracting interpretable syllables, they don’t account for forms of behavioral variability. To address this and capitalize on the information in the enormous volume (8 billion frames) of data, I exploit large language models to generate a behavioral embedding using condensed action labels from the Inception3D AR model. Preliminary results from the combination of both approaches are promising; the system can distinguish behaviors in control and experimental specimens exposed to trauma.
Technologies Used: PyTorch, Signal Processing, YOLO, VideoProcessing, opencv.
My Role:
- Trained a temporal LSTM classifier on action labels, experimented with different grouping intervals of predicted actions (15min, 30min, 60min) to see if we can reduce the noise.
- Built an AutoEncoder for full-frame videos, and came up with the per-pixel entropy weighting loss to detect the moving mice by taking per-pixel entropy. Clustering and visualizing Latents: tSNE, U-MAP, PCA.
- Explainability (gradient analysis) to explain confounds, background subtraction, and segmentation on the videos: Transformers and Optical Flow.
- Annotated over 20,000 frames overall for DeepLabCut and bootstrapped DeepLabCuts Models for individual animals.
- Built a tracker for the animals, using signal processing (Kalman filter and Savitzky-Golay filters) for tracking, and eliminating Jitter. Fine-tuned YOLOv5 and SSD for object detection
- Trained a beta-VAE and conditional-VAE on the cropped frames. Debugged the VAE, and finally got it working on the data. Built a Recurrent Pose VAE to learn pose dynamics and transitions. Running Auto-regressive HMM models on the latents
- Projected the actions into LLM space and training Language models for MaskedLanguageModelling and Sequence Classification.
Spine Extraction for Behavioral Analysis from Unlabelled Videos
Project Gallery
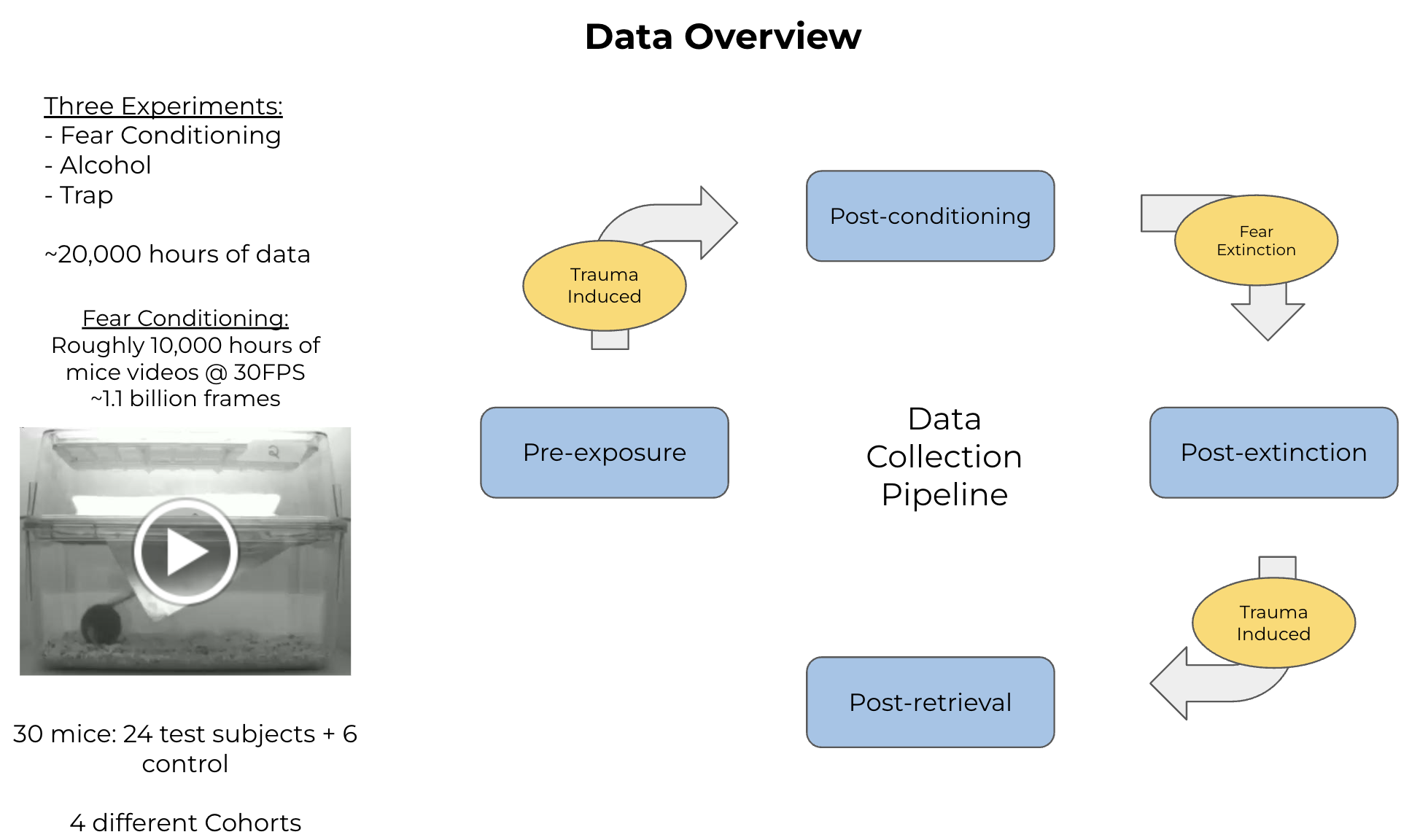
Data Overview
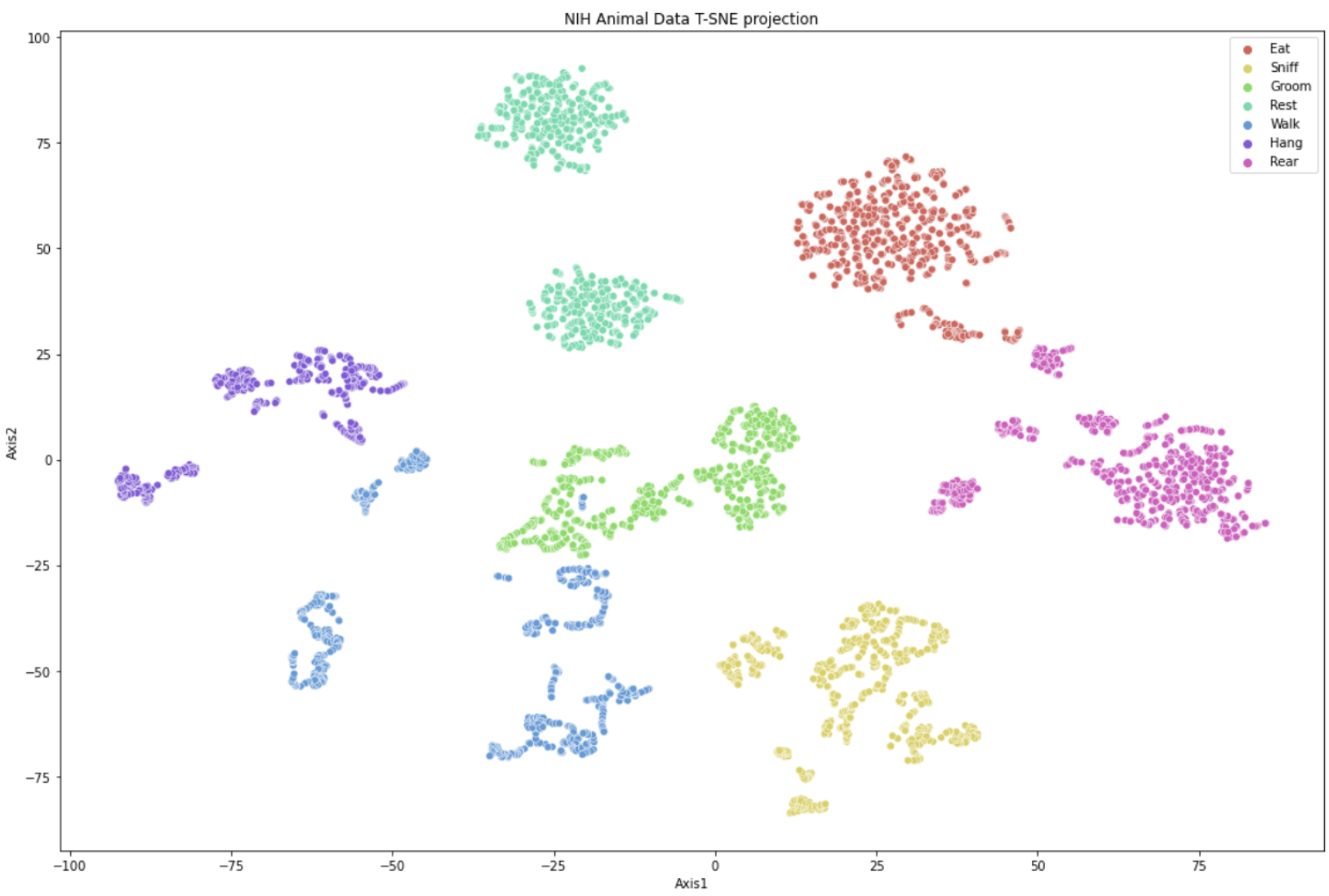
Animal Actions Disambiguated
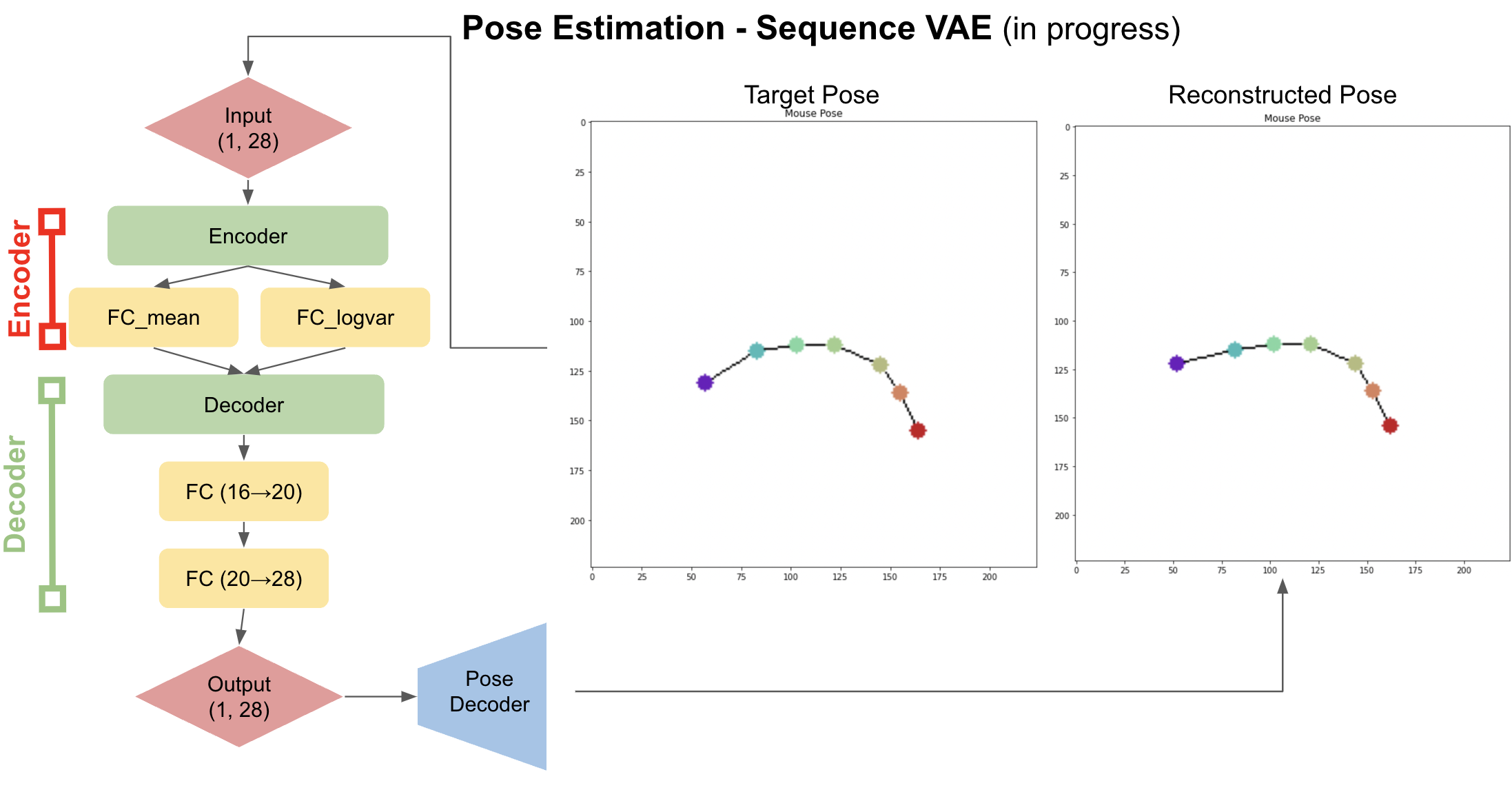
Variational Autoencoder for Pose
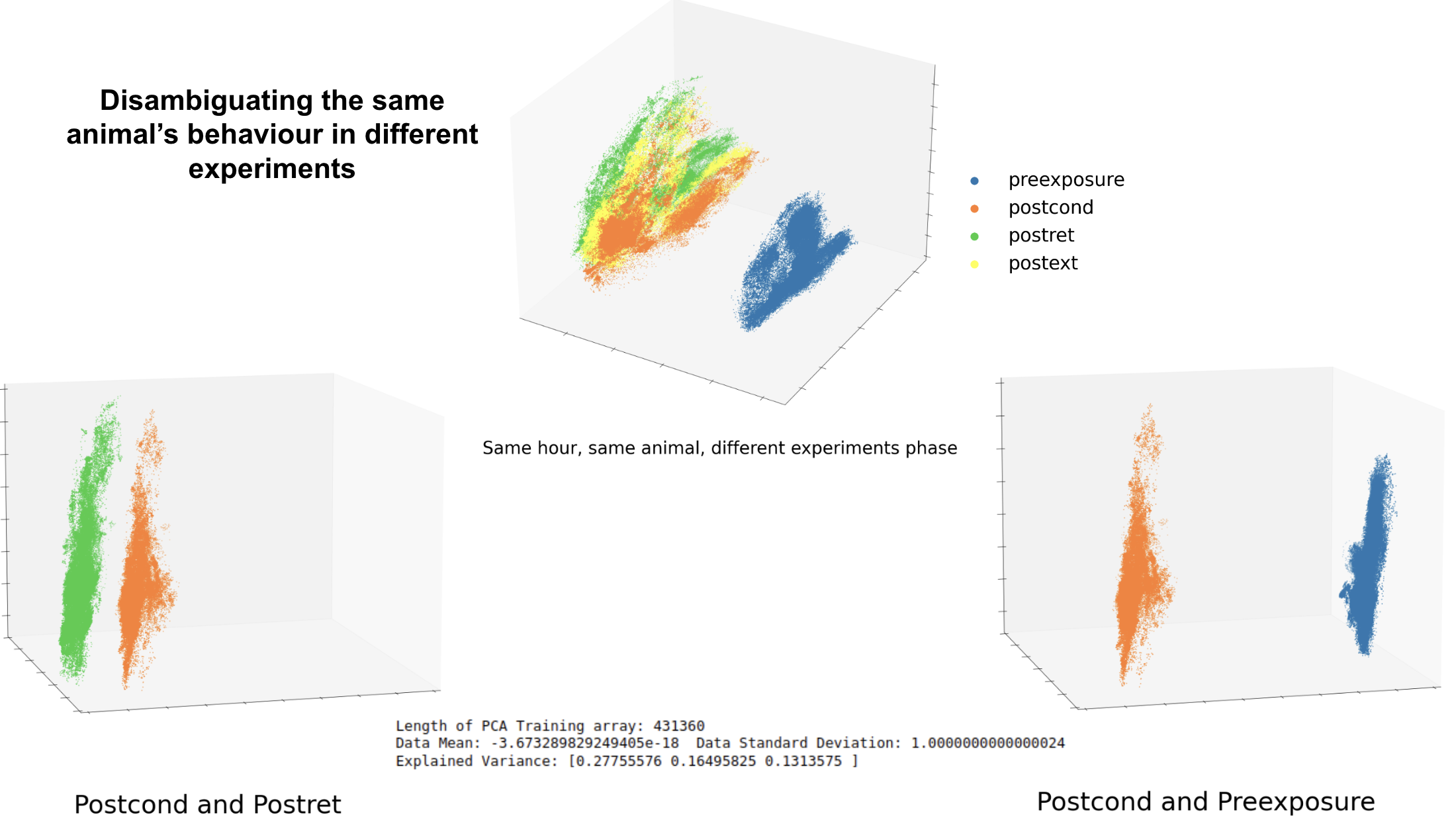
Distinguishing Experimental Phases
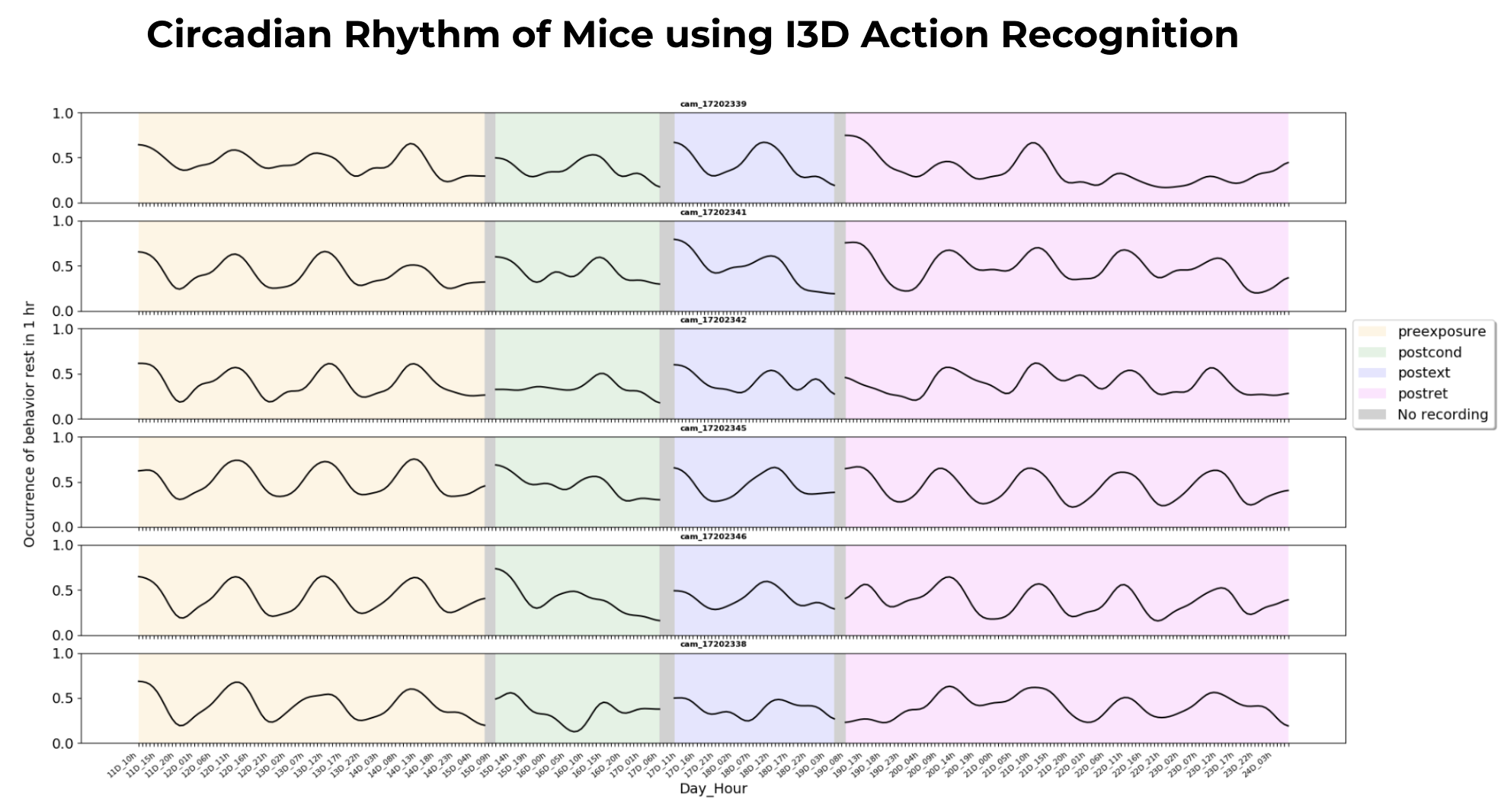
Circadian Rhythm of Mice from I3D Action Recognition
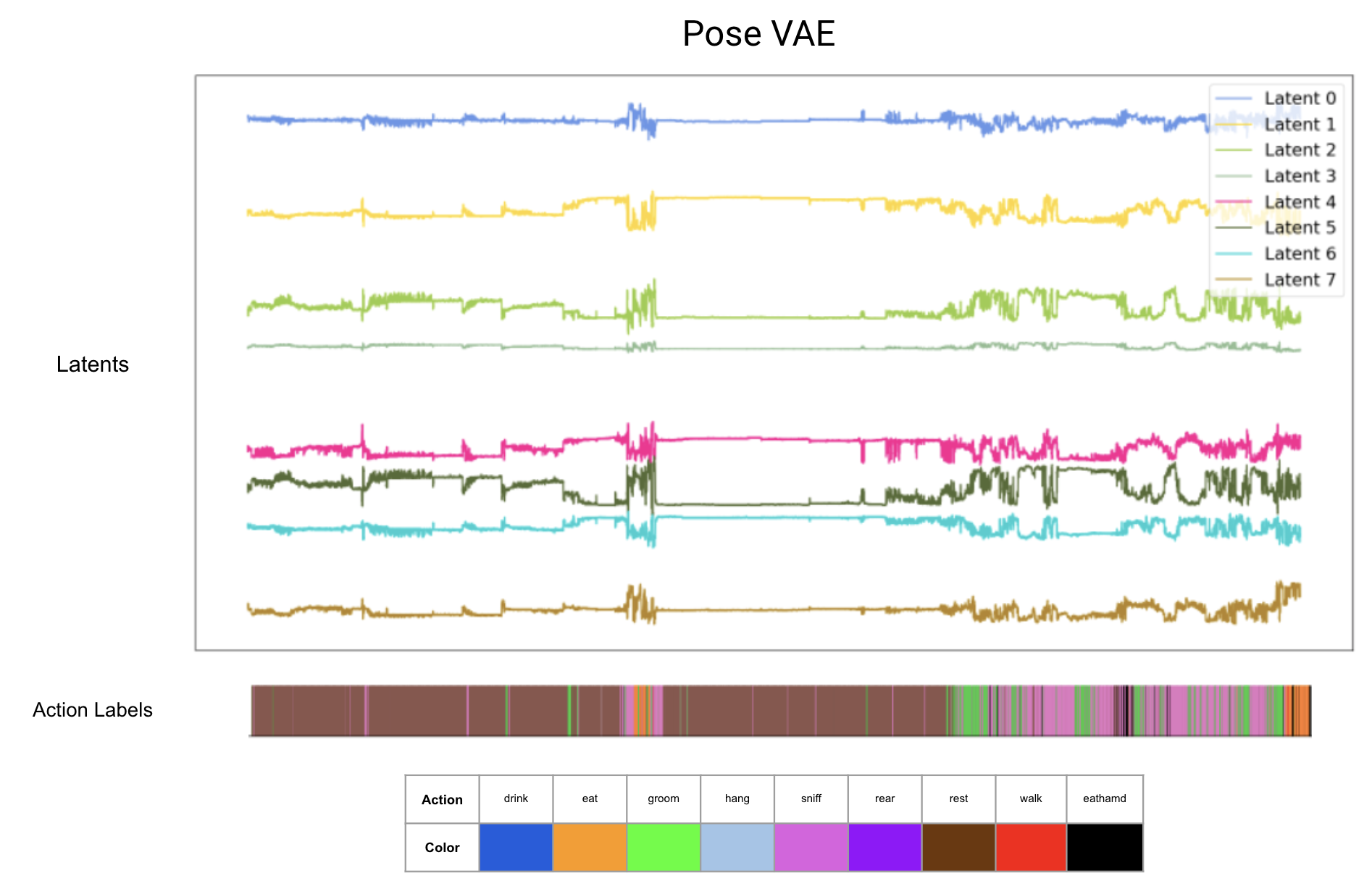
Distinguishing Fine-grained Spine Positions